Section 7 Genome Length Sweep
By default, all genomes are bitstrings with 100 bits. Here, we look into the effects of varying this genome length using lengths of 25, 50, 100, 200, and 400 bits. Regardless of genome length, the restraint threshold was set at 60% of the genome being 1s and all organisms started at a restraint buffer of 0.
The configuration script and data for the experiment can be found under 2021_02_27__genome_length/ in the experiments directory of the git repository.
7.1 Data cleaning
Load necessary libraries
library(dplyr)
library(ggplot2)
library(ggridges)
library(scales)
library(khroma)Load the data and trim include only the final generation data for sizes 16x16 to 512x512.
# Load the data
df = read.csv('../experiments/2021_02_27__genome_length/evolution/data/scraped_evolution_data_length_50.csv')
df = rbind(df, read.csv('../experiments/2021_02_27__genome_length/evolution/data/scraped_evolution_data_length_200.csv'))
df = rbind(df, read.csv('../experiments/2021_02_27__genome_length/evolution/data/scraped_evolution_data_length_100.csv'))
df = rbind(df, read.csv('../experiments/2021_02_27__genome_length/evolution/data/scraped_evolution_data_length_400.csv'))
df = rbind(df, read.csv('../experiments/2021_02_27__genome_length/evolution/data/scraped_evolution_data_length_25.csv'))
# Trim off NAs (artifacts of how we scraped the data) and trim to only have gen 10,000
df2 = df[!is.na(df$MCSIZE) & df$generation == 10000,]
# Ignore data for size 8x8 and 1024x1024
df2 = df2[df2$MCSIZE != 8 & df2$MCSIZE != 1024,]We group and summarize the data to ensure all replicates are present.
# Group the data by size and summarize
data_grouped = dplyr::group_by(df2, MCSIZE, LENGTH)
data_summary = dplyr::summarize(data_grouped, mean_ones = mean(ave_ones), n = dplyr::n())## `summarise()` has grouped output by 'MCSIZE'. You can override using the `.groups` argument.We clean the data and create a few helper variables to make plotting easier.
## Set variables to make plotting easier
# Calculate restraint value (x - 60% of the genome length)
df2$restraint_value = df2$ave_ones - (df2$LENGTH * 0.6)
# Make a nice, clean factor for size
df2$size_str = paste0(df2$MCSIZE, 'x', df2$MCSIZE)
df2$size_factor = factor(df2$size_str, levels = c('16x16', '32x32', '64x64', '128x128', '256x256', '512x512', '1024x1024'))
df2$size_factor_reversed = factor(df2$size_str, levels = rev(c('16x16', '32x32', '64x64', '128x128', '256x256', '512x512', '1024x1024')))
df2$length_str = paste0(df2$LENGTH, '-bit')
df2$length_factor = factor(df2$length_str, levels = c('25-bit', '50-bit', '100-bit', '200-bit', '400-bit'))
data_summary$size_str = paste0(data_summary$MCSIZE, 'x', data_summary$MCSIZE)
data_summary$size_factor = factor(data_summary$size_str, levels = c('16x16', '32x32', '64x64', '128x128', '256x256', '512x512', '1024x1024'))
data_summary$length_str = paste0(data_summary$LENGTH, '-bit')
data_summary$length_factor = factor(data_summary$length_str, levels = c('25-bit', '50-bit', '100-bit', '200-bit', '400-bit'))
# Create a map of colors we'll use to plot the different organism sizes
color_vec = as.character(khroma::color('bright')(7))
color_map = c(
'16x16' = color_vec[1],
'32x32' = color_vec[2],
'64x64' = color_vec[3],
'128x128' = color_vec[4],
'256x256' = color_vec[5],
'512x512' = color_vec[6],
'1024x1024' = color_vec[7]
)
# Set the sizes for text in plots
text_major_size = 18
text_minor_size = 16 7.2 Data integrity check
Now we plot the number of finished replicates for each treatment to make sure all data are present.
Each row shows a different genome length (in bits).
Each bar/color shows a different organism size.
7.3 Aggregate plots
7.3.1 Facet by genome length
Here we plot all the data at once. Each row shows a different genome length and each boxplot shows a given organism size.
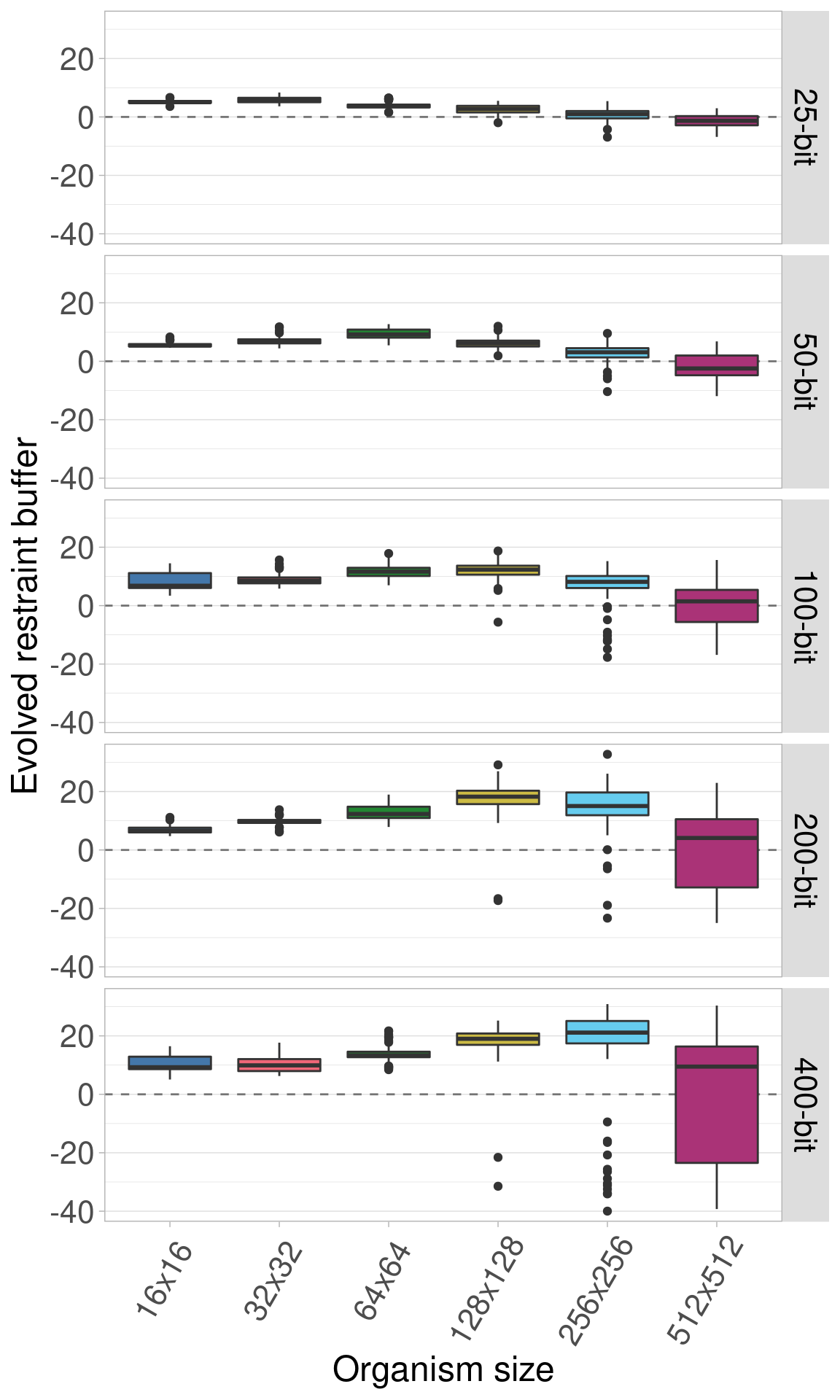
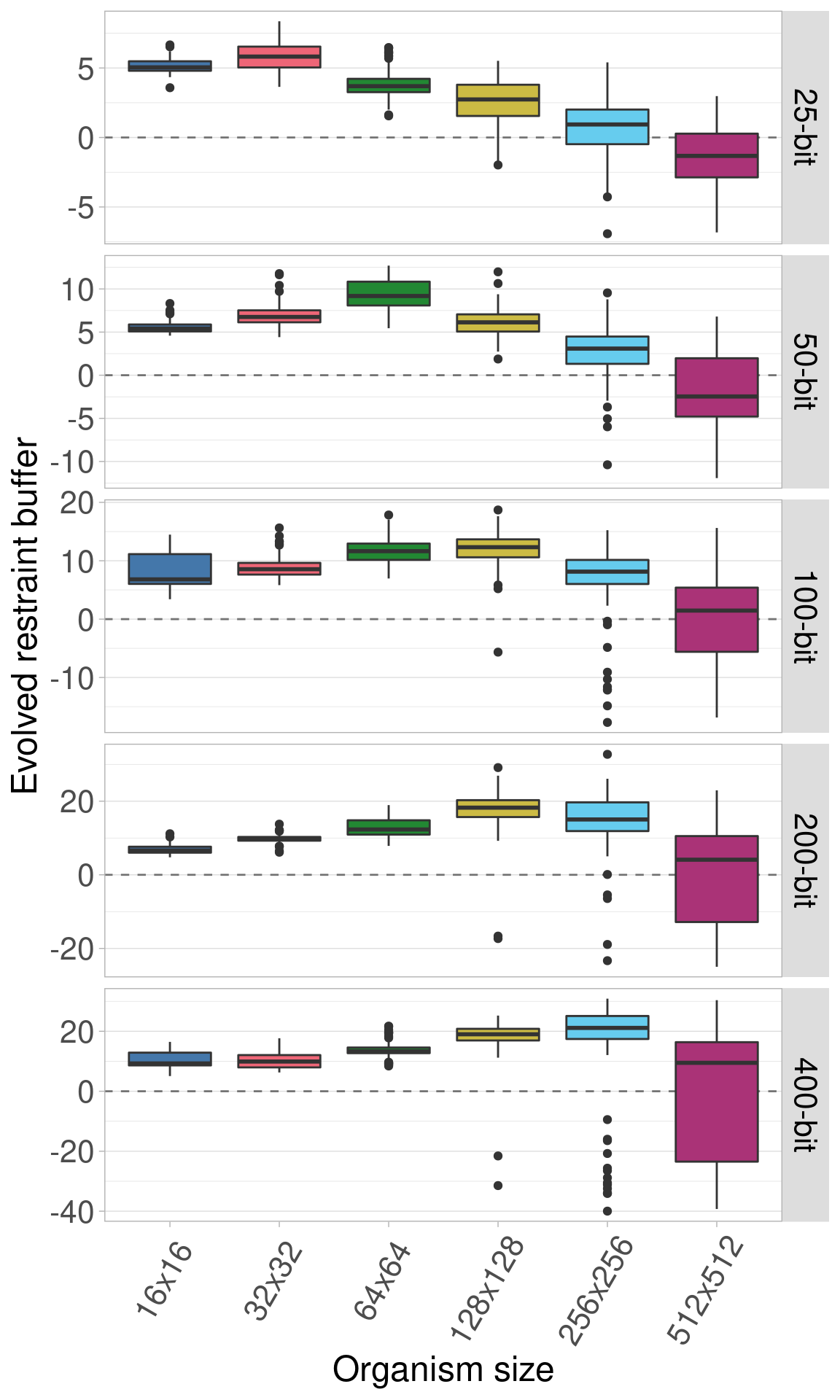
Here we plot the same data, only we allow the y-axis to vary between rows.
7.3.2 Facet by organism size
Here we plot the same data again, only now each row shows an organism size while genome length varies on the x-axis.
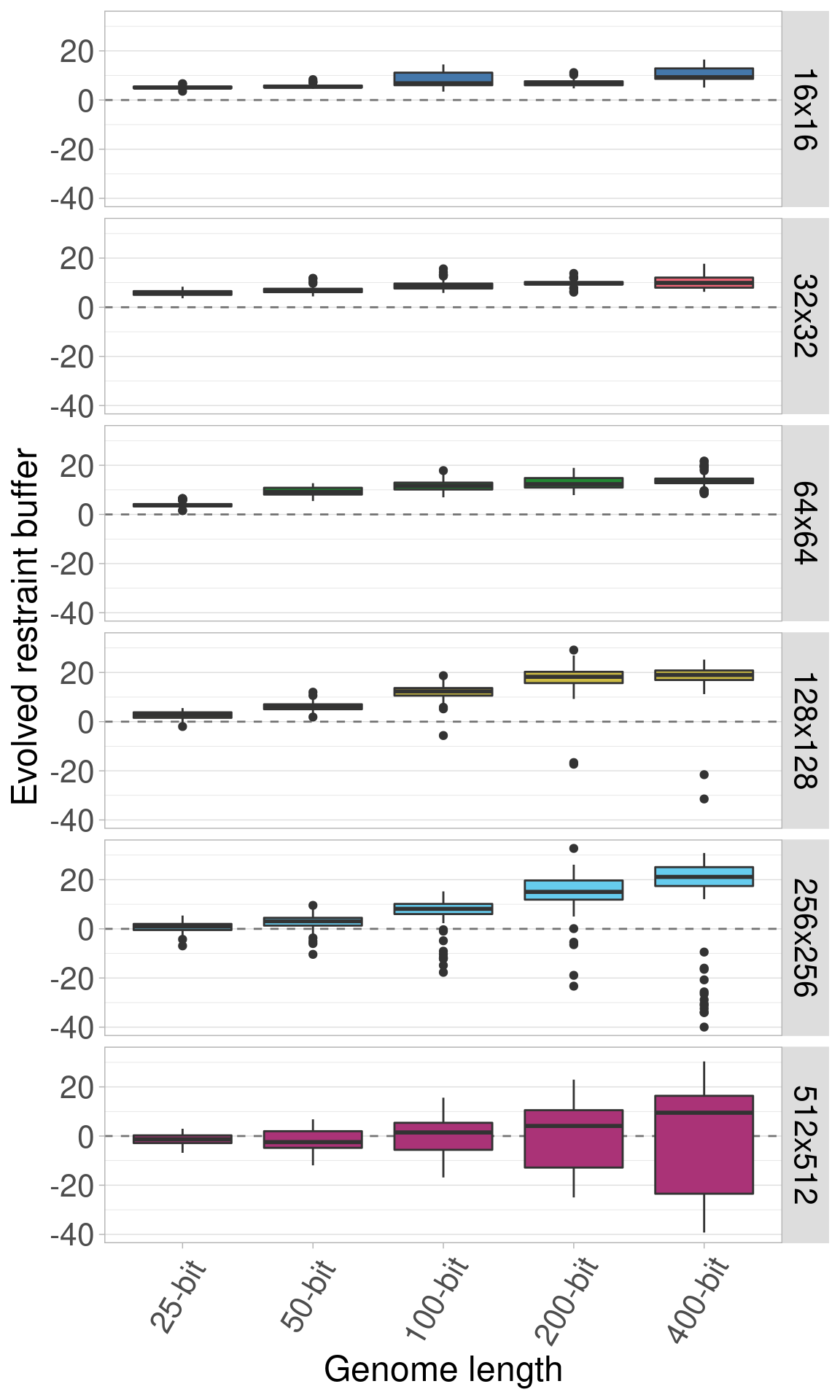
Here is the identical plot, but now we allow the y-axis to vary between the rows.
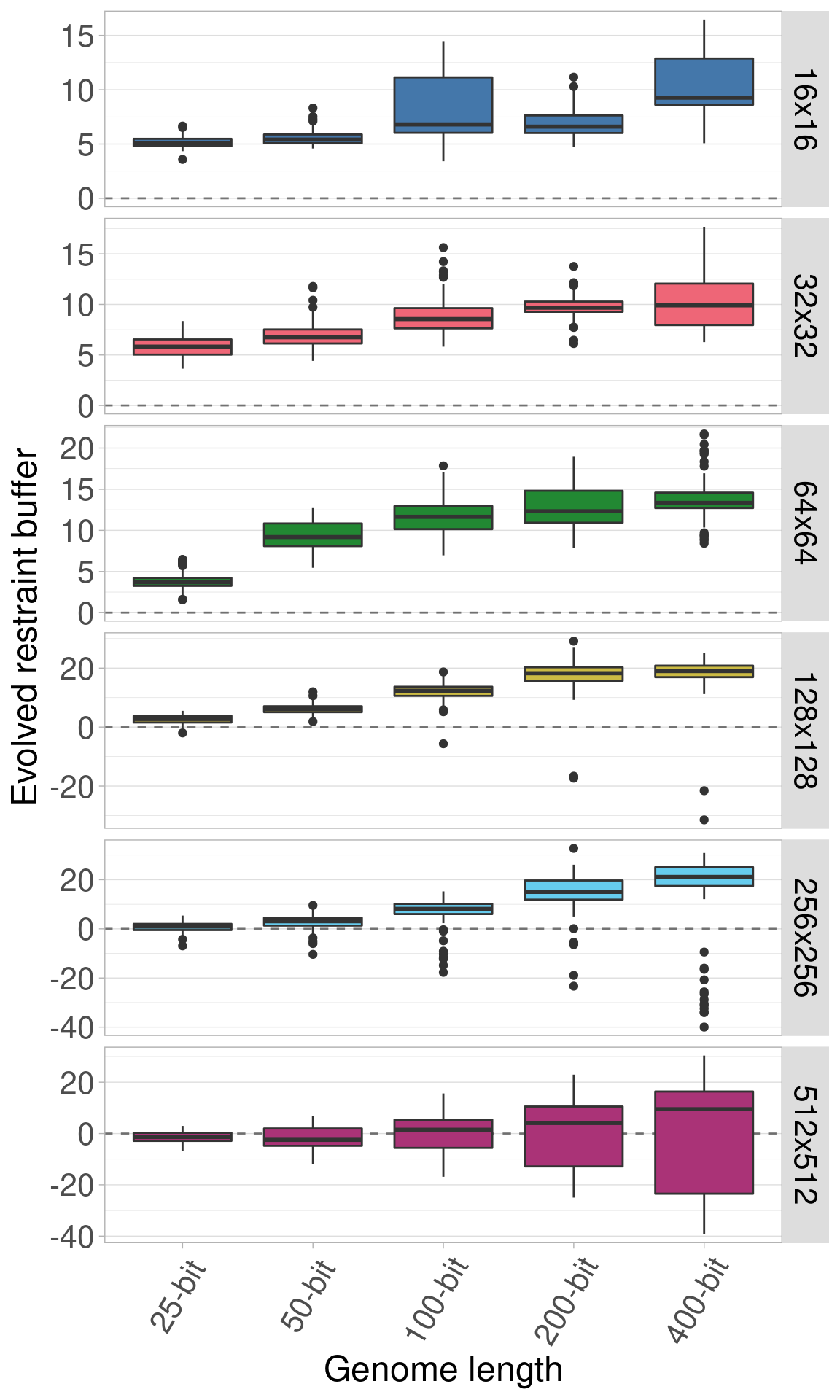
7.4 Single organism size plots
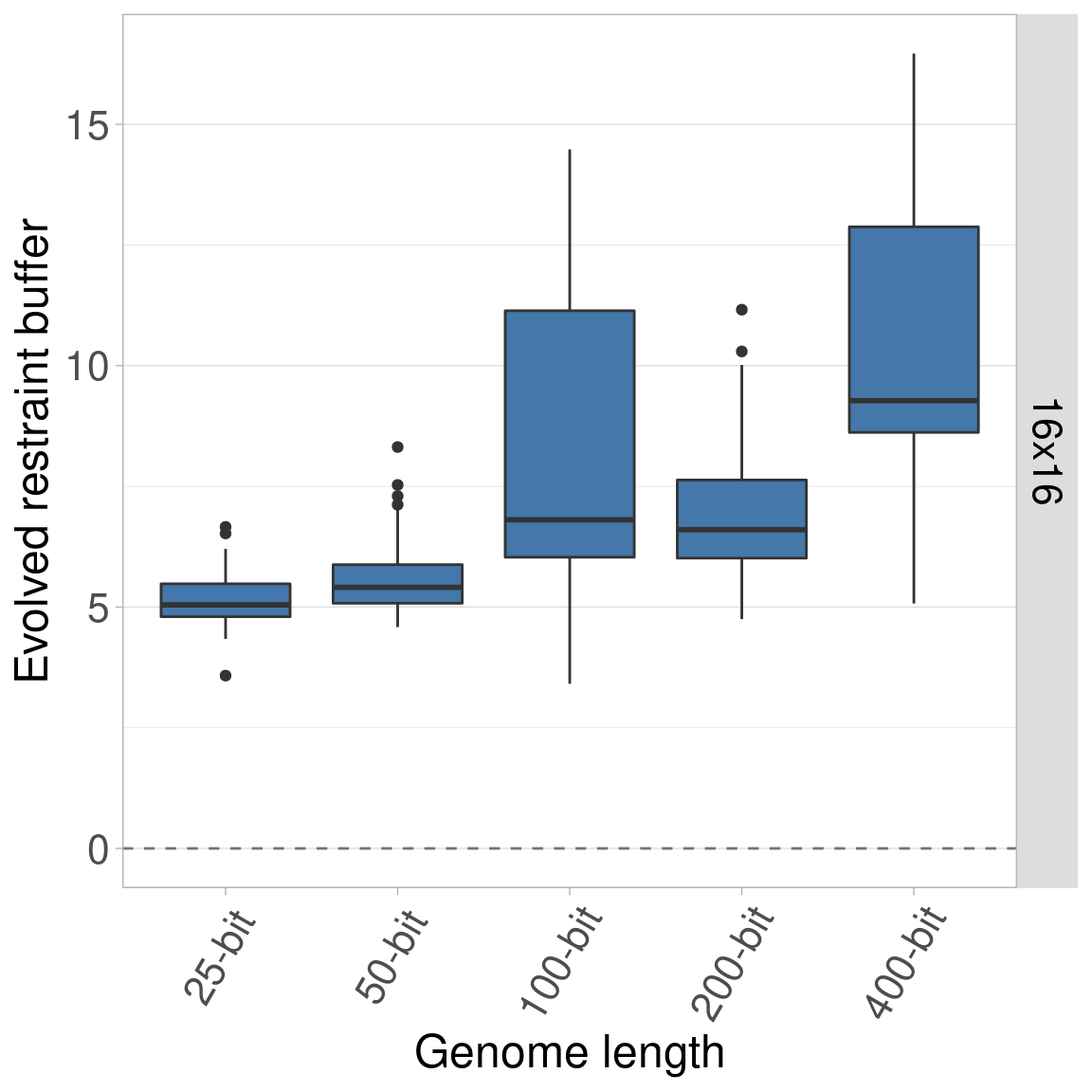
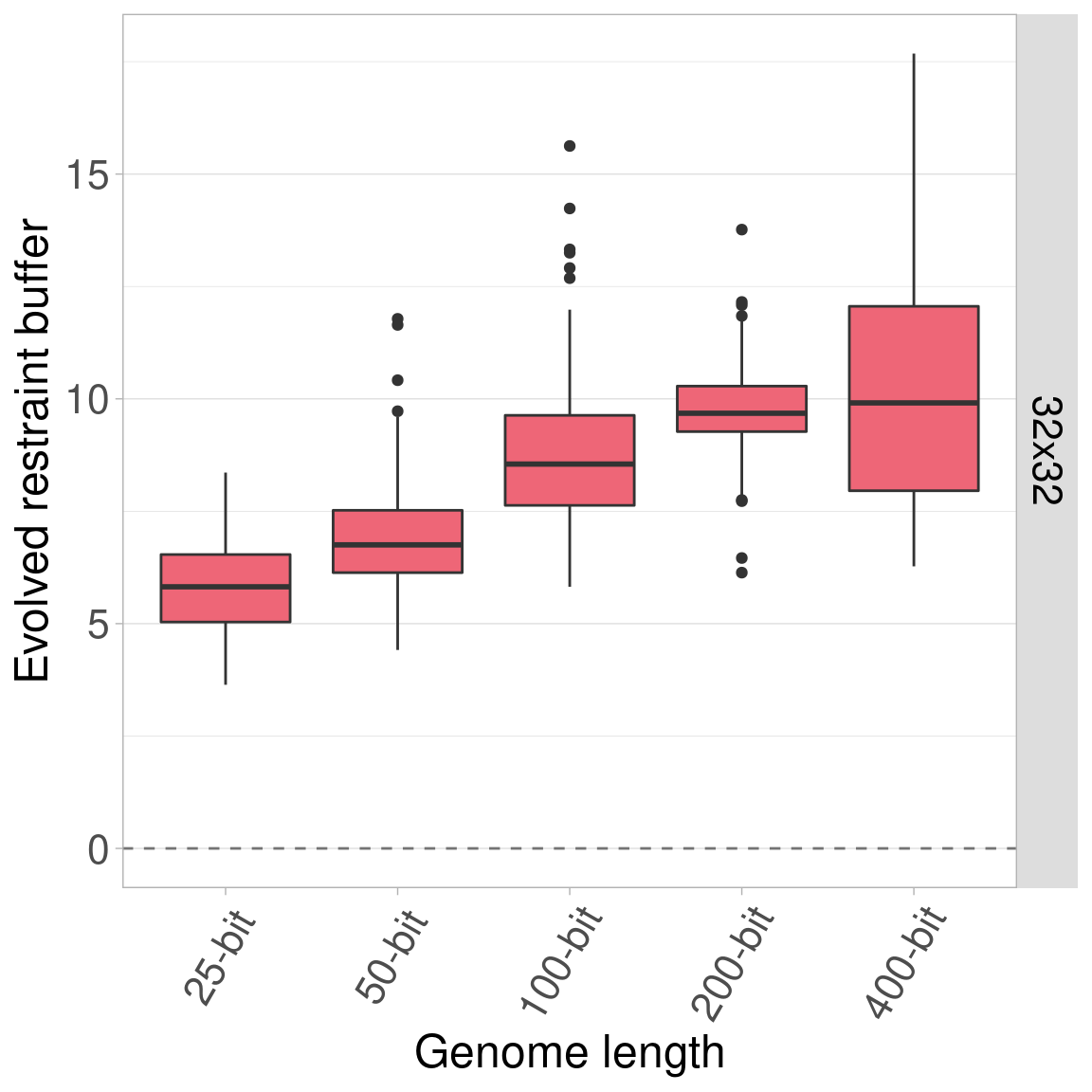
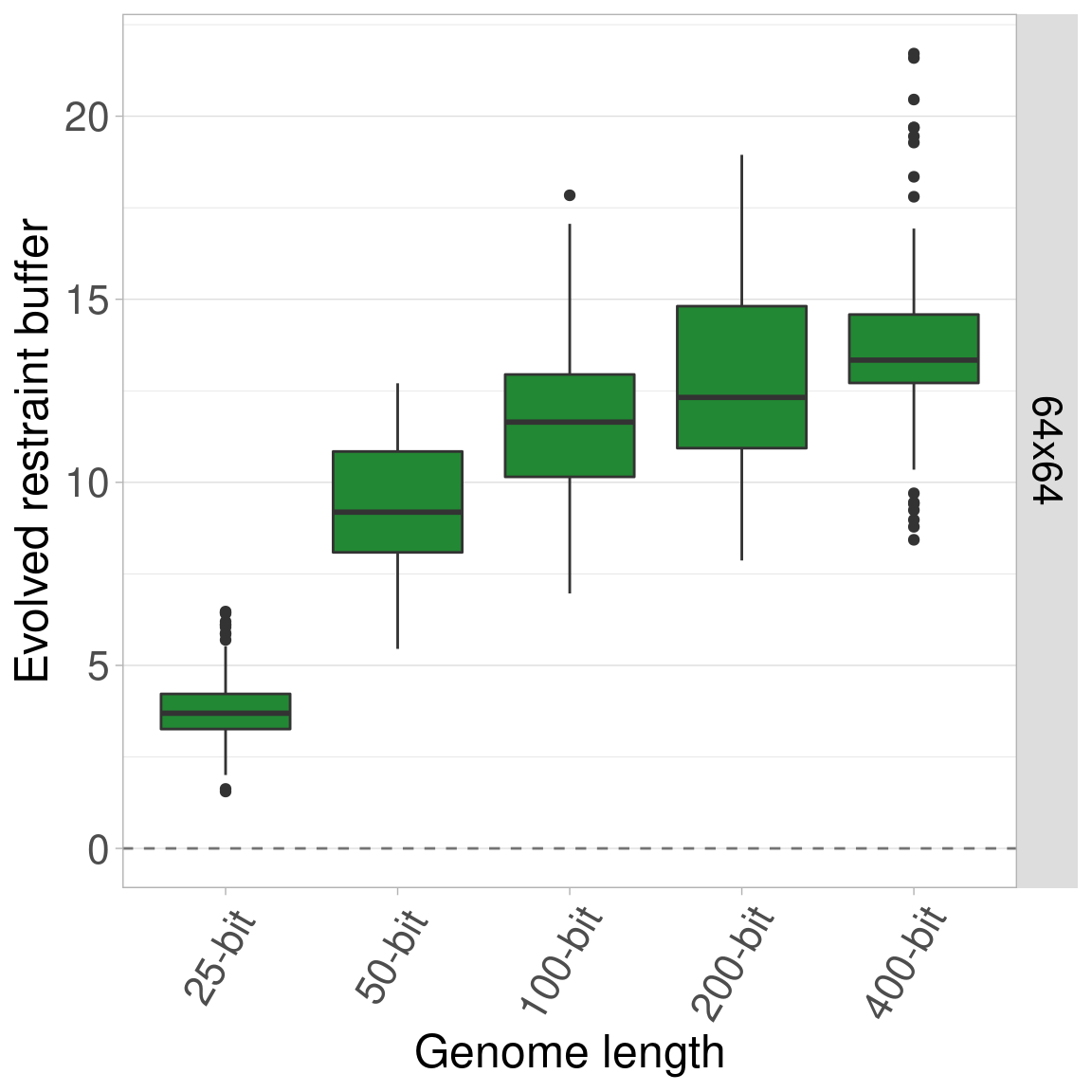
Here we plot each organism size independently, with the genome length on the x-axis.
7.4.1 Organism size 16x16
7.4.2 Organism size 32x32
7.4.3 Organism size 64x64
7.4.4 Organism size 128x128
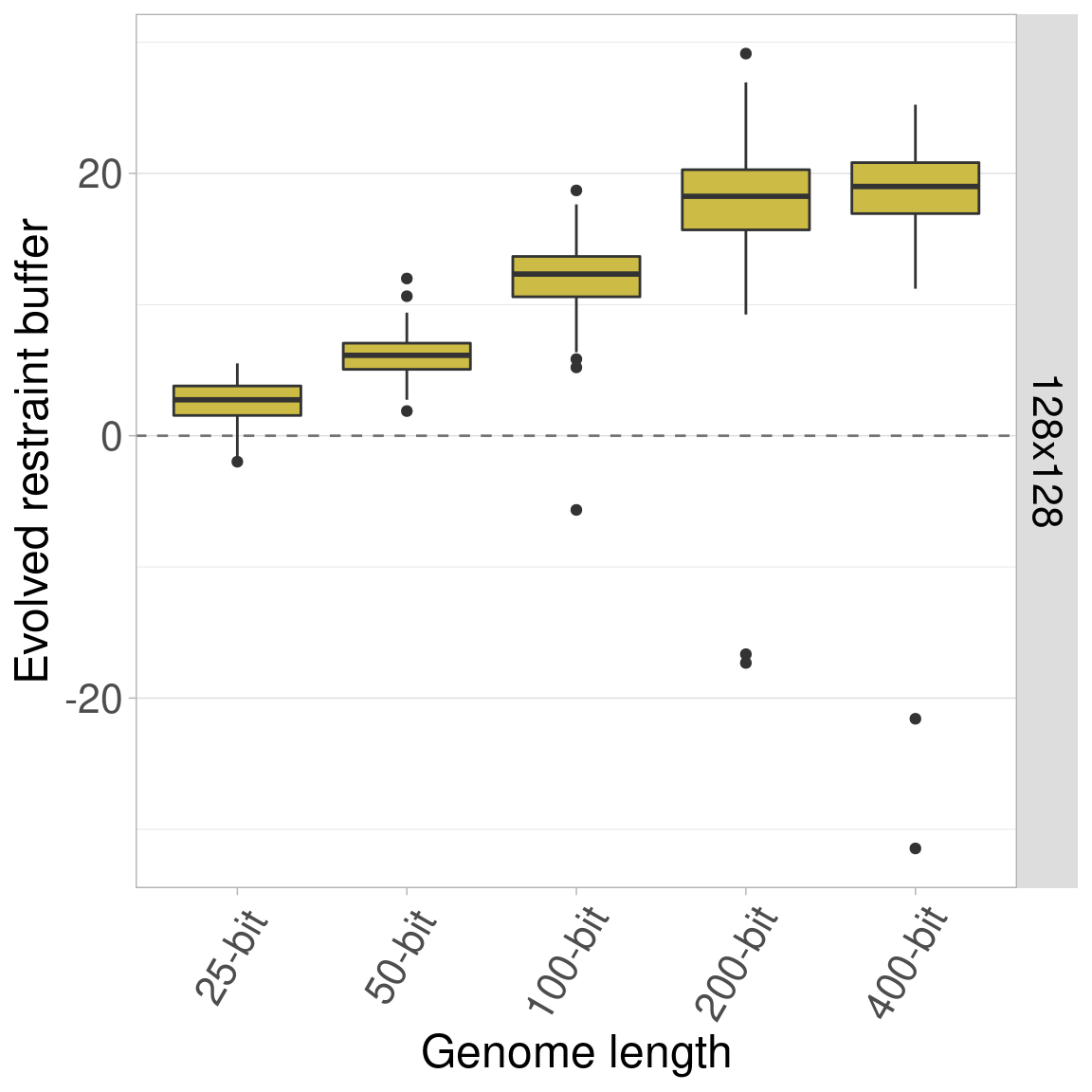
7.4.5 Organism size 256x256
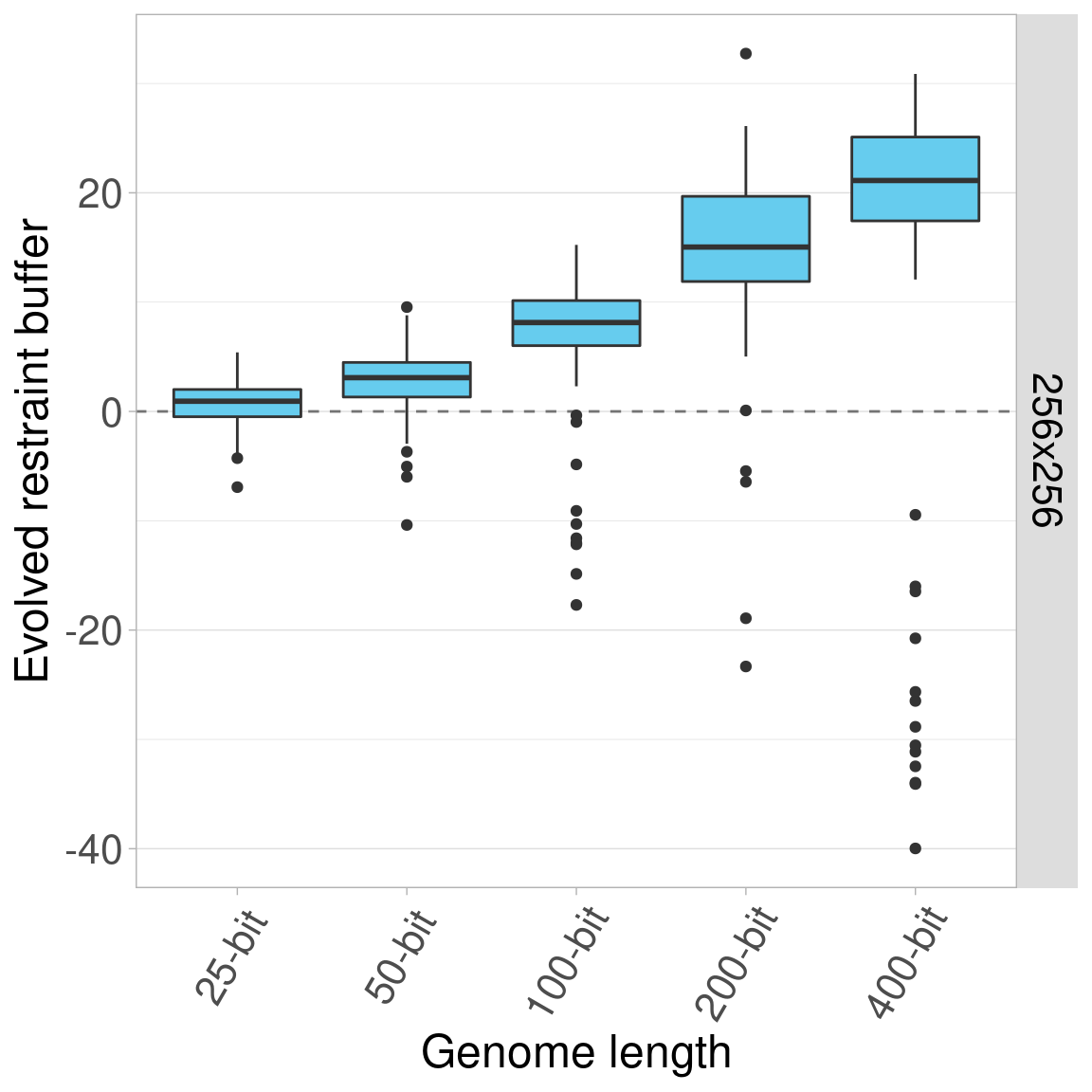
7.4.6 Organism size 512x512
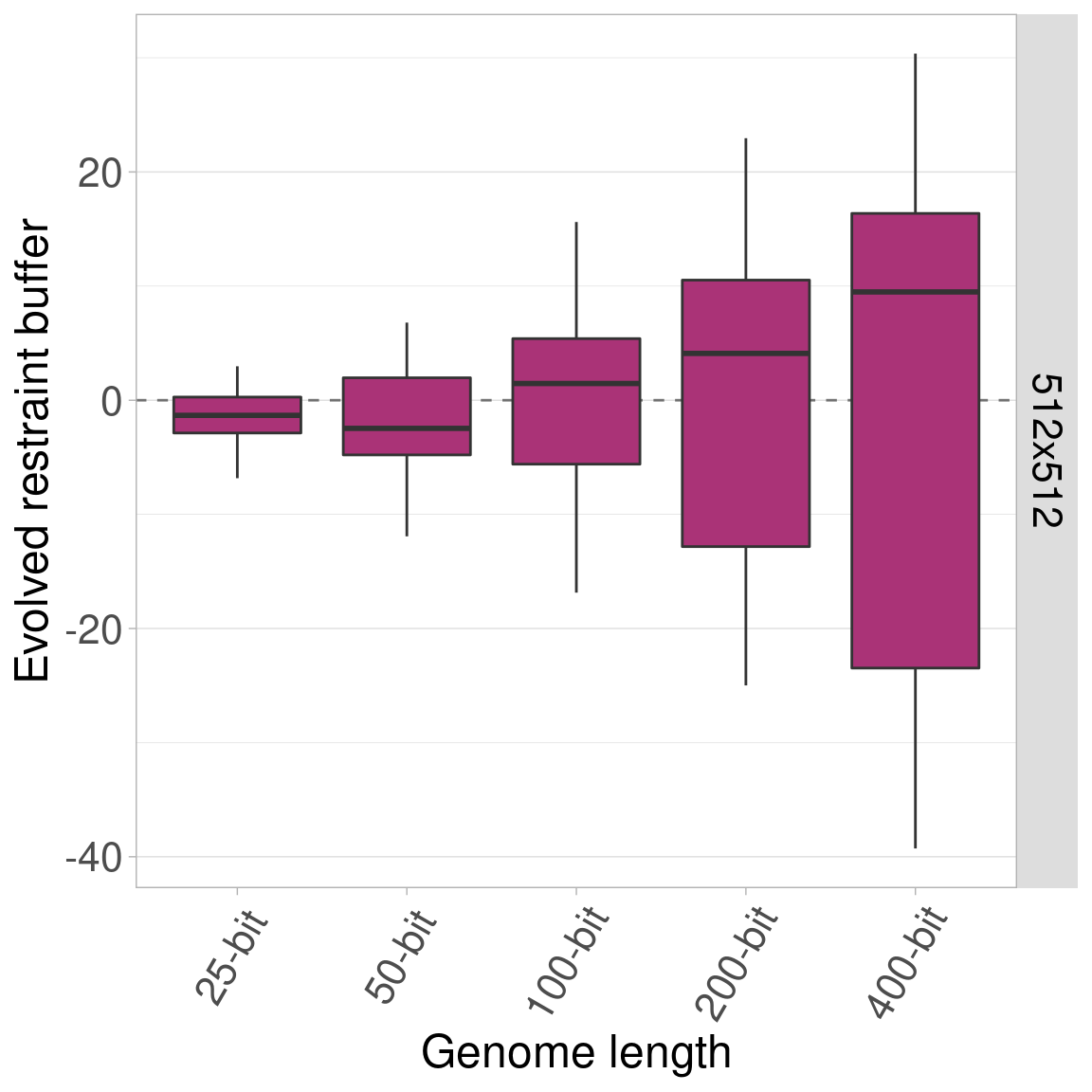
7.5 Single genome length plots
Here we plot each genome length independently, with the organism size on the x-axis.
7.5.1 25-bit genomes
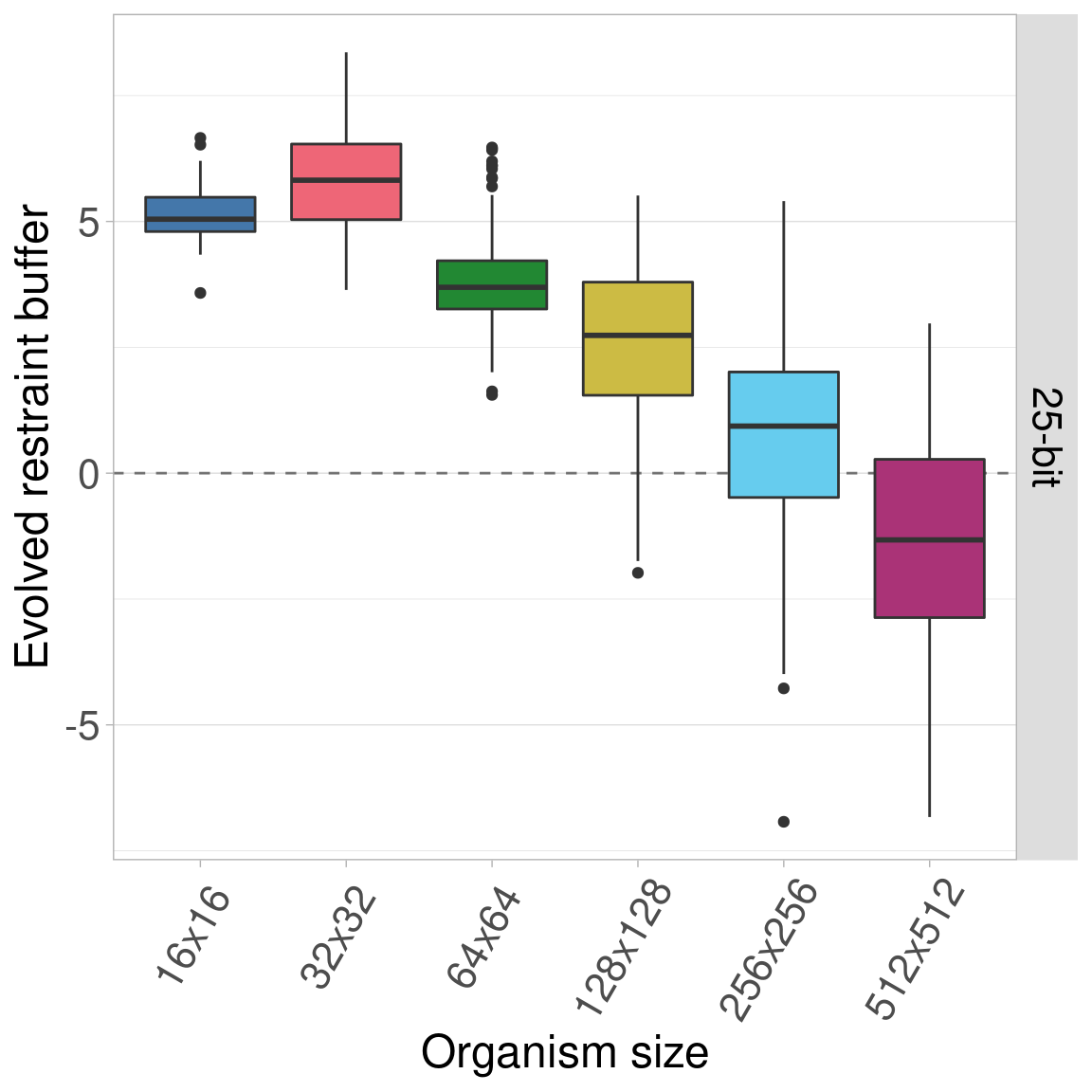
7.5.2 50-bit genomes
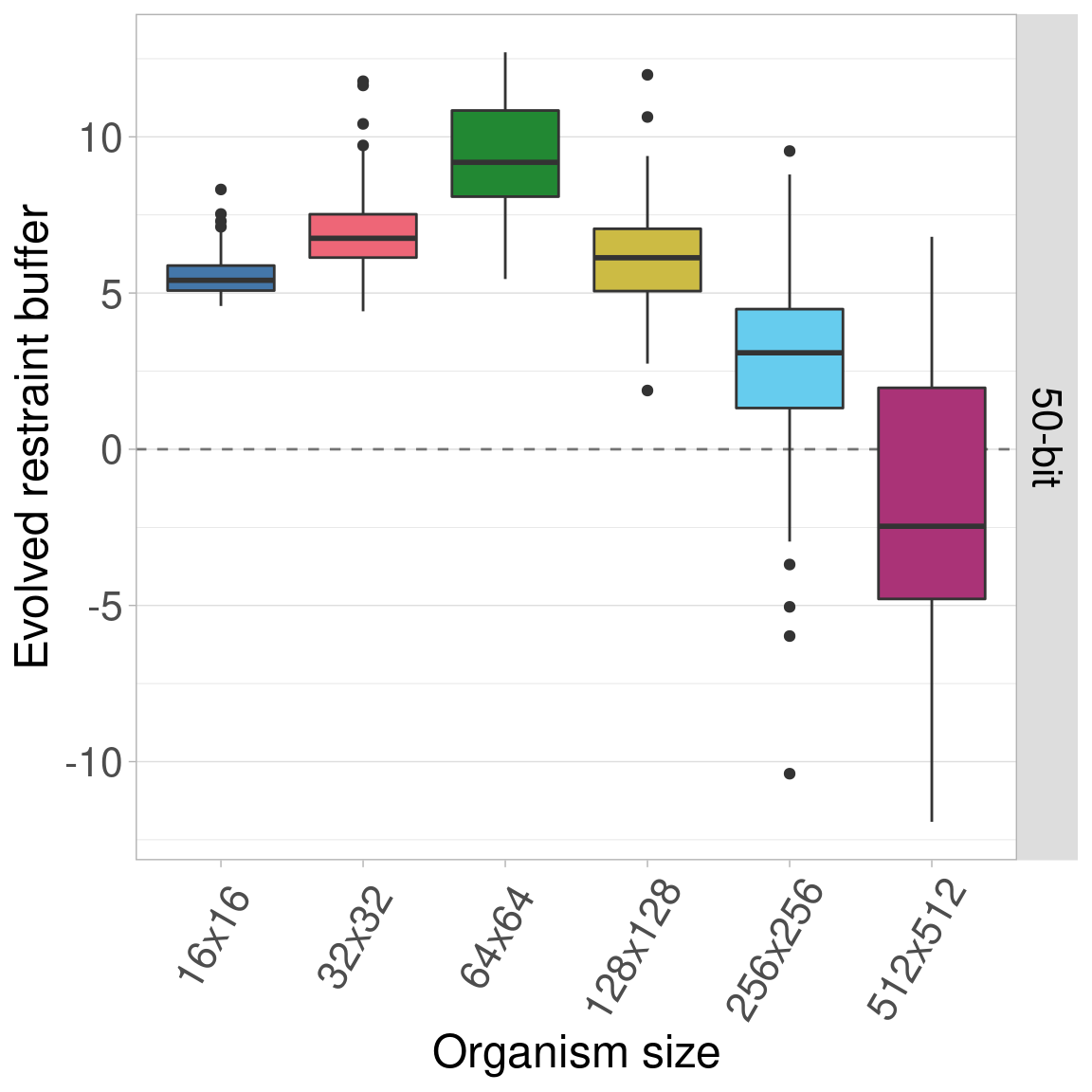
7.5.3 100-bit genomes
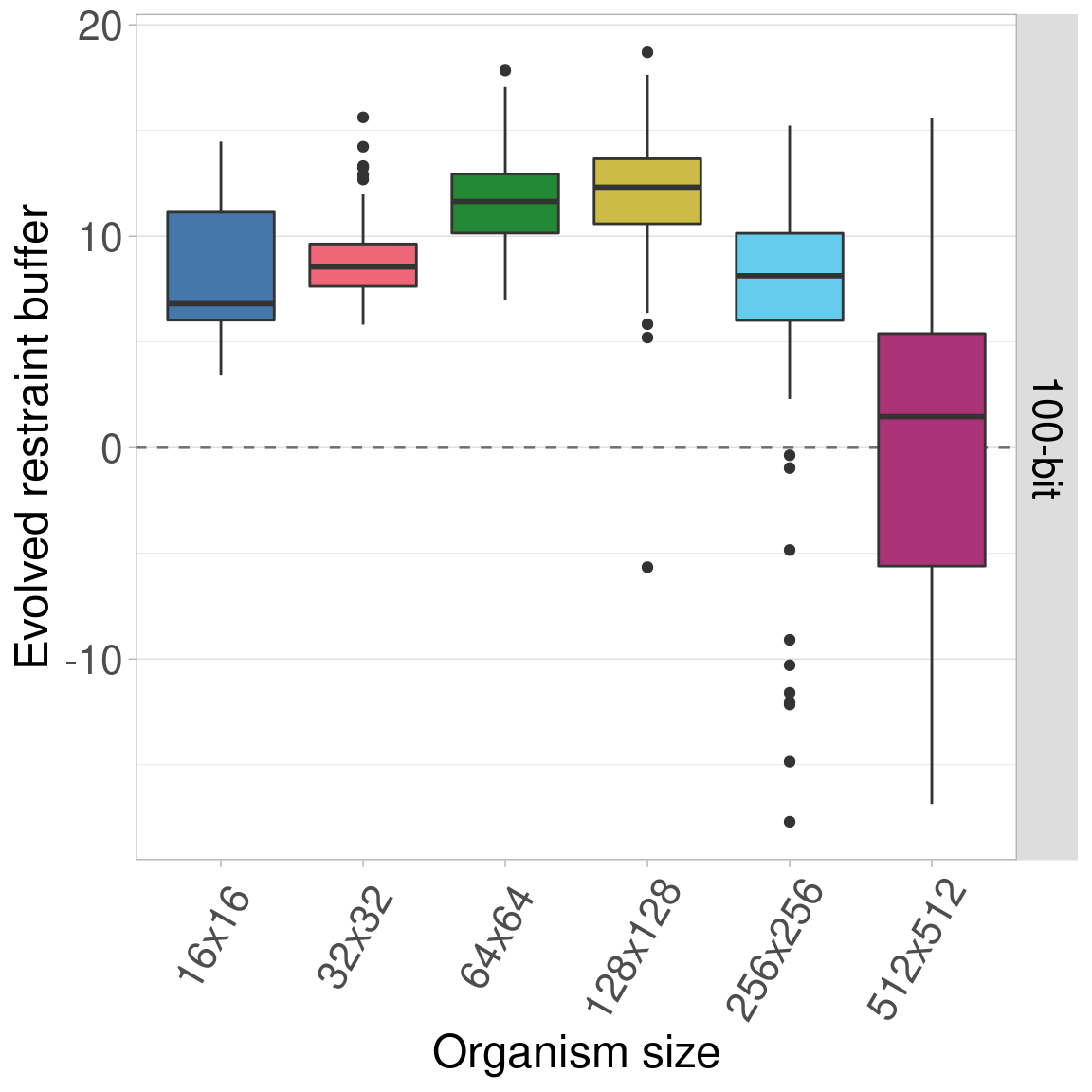
7.5.4 200-bit genomes
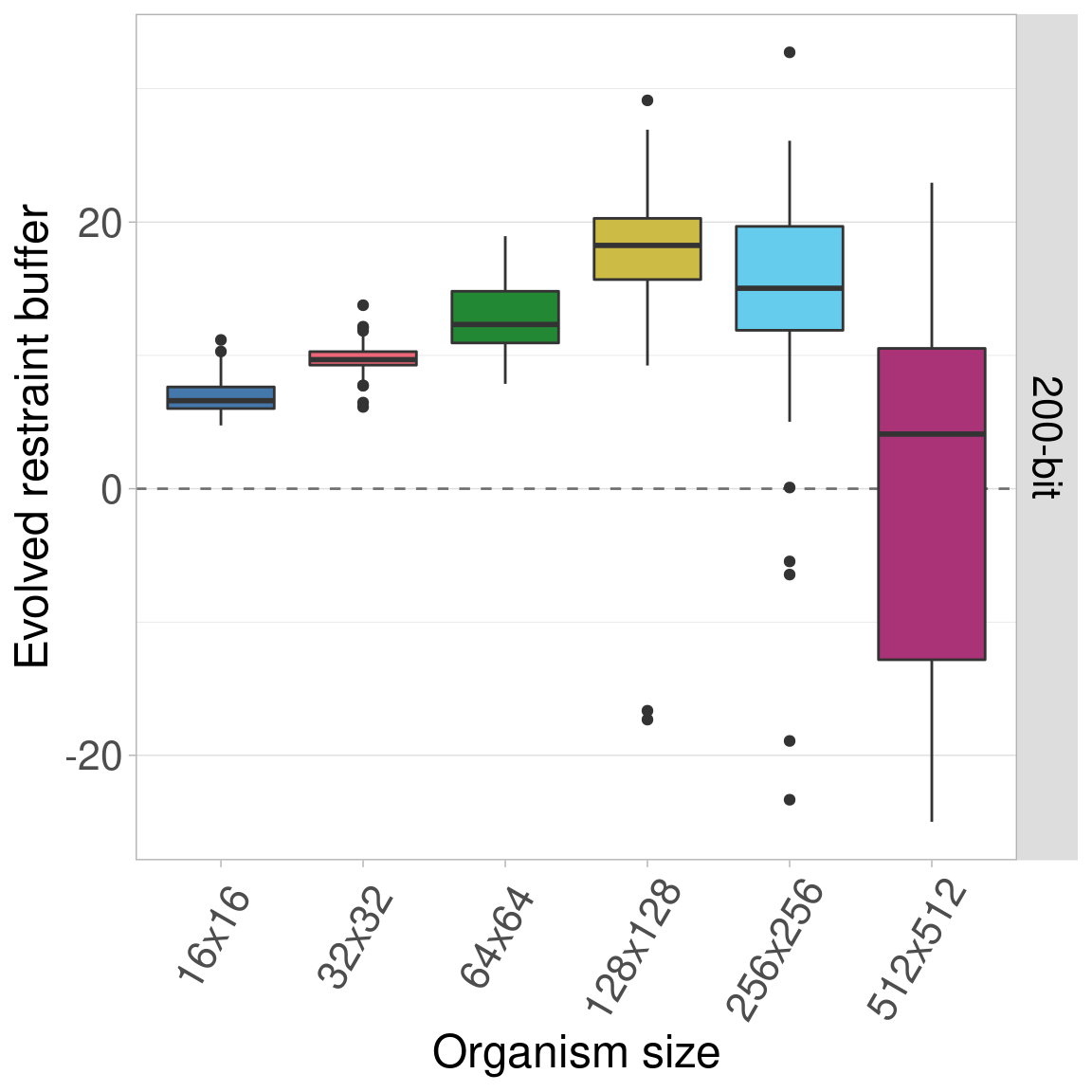
7.5.5 400-bit genomes
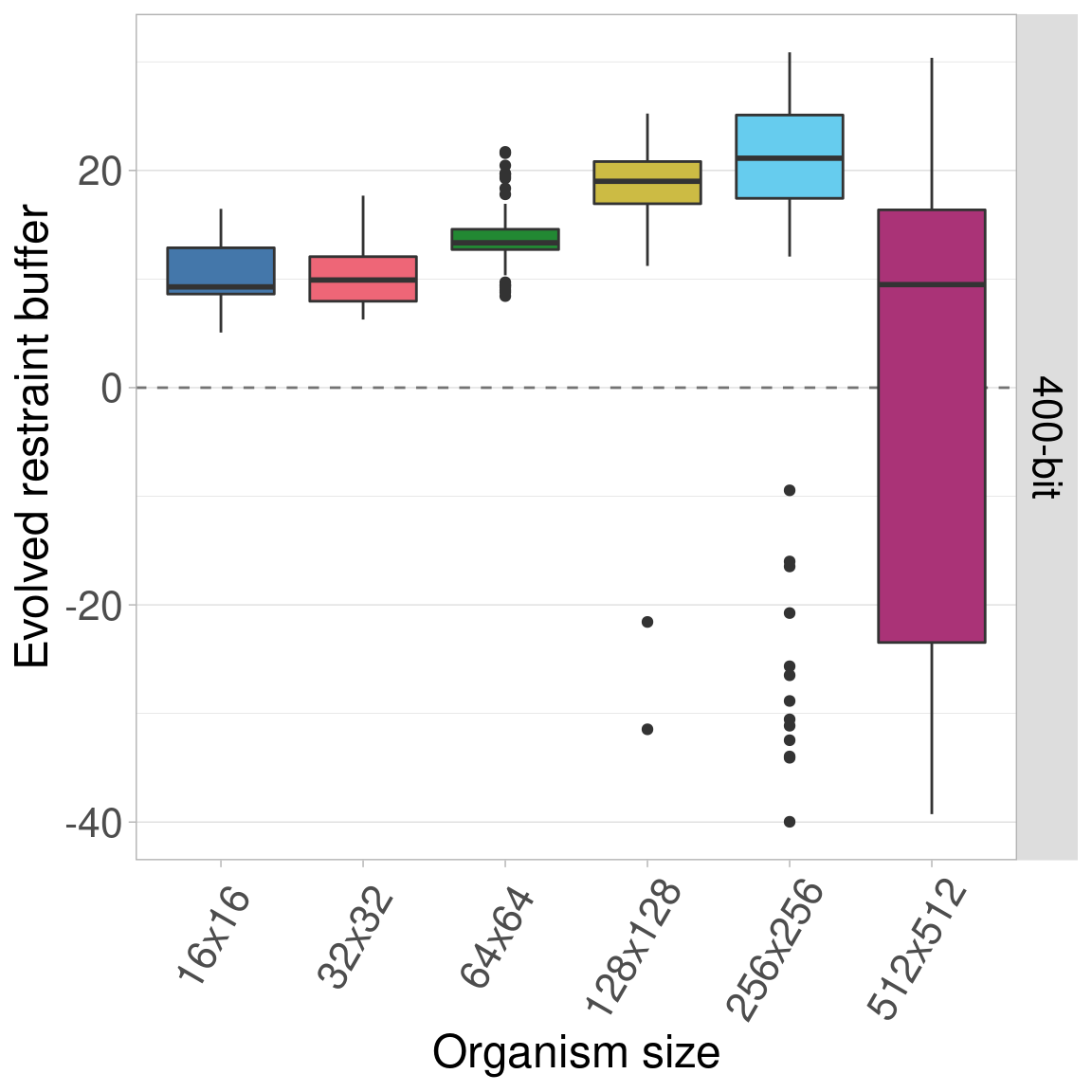
7.6 Statistics
Since organism size is our main point of comparison, we calculate statistics for each genome length.
First, we perform a Kruskal-Wallis test across all organism sizes to indicate if variance exists at that mutation rate. If variance exists, we then perform a pairwise Wilcoxon Rank-Sum test to show which pairs of organism sizes significantly differ. Finally, we perform Bonferroni-Holm corrections for multiple comparisons.
length_vec = c(25, 50, 100, 200, 400)
df_kruskal = data.frame(data = matrix(nrow = 0, ncol = 4))
colnames(df_kruskal) = c('genome_length', 'p_value', 'chi_squared', 'df')
for(genome_length in length_vec){
df_test = df2[df2$LENGTH == genome_length,]
res = kruskal.test(df_test$restraint_value ~ df_test$MCSIZE, df_test)
df_kruskal[nrow(df_kruskal) + 1,] = c(genome_length, res$p.value, as.numeric(res$statistic)[1], as.numeric(res$parameter)[1])
}
df_kruskal$less_0.01 = df_kruskal$p_value < 0.01
print(df_kruskal)## genome_length p_value chi_squared df less_0.01
## 1 25 1.508889e-97 461.6473 5 TRUE
## 2 50 9.772852e-87 411.5159 5 TRUE
## 3 100 7.491319e-60 286.6294 5 TRUE
## 4 200 1.626963e-75 359.4358 5 TRUE
## 5 400 2.857912e-49 237.3380 5 TRUEWe see that significant variation exists within each genome length, so we perform pairwise Wilcoxon tests on each to see which pairs of sizes are significantly different.
size_vec = c(16, 32, 64, 128, 256, 512)
length_vec = c(25, 50, 100, 200, 400)
for(genome_length in length_vec){
df_test = df2[df2$LENGTH == genome_length,]
df_wilcox = data.frame(data = matrix(nrow = 0, ncol = 6))
colnames(df_wilcox) = c('genome_length', 'size_a', 'size_b', 'p_value_corrected', 'p_value_raw', 'W')
for(size_idx_a in 1:(length(size_vec) - 1)){
size_a = size_vec[size_idx_a]
for(size_idx_b in (size_idx_a + 1):length(size_vec)){
size_b = size_vec[size_idx_b]
res = wilcox.test(df_test[df_test$MCSIZE == size_a,]$restraint_value, df_test[df_test$MCSIZE == size_b,]$restraint_value, alternative = 'two.sided')
df_wilcox[nrow(df_wilcox) + 1,] = c(genome_length, size_a, size_b, 0, res$p.value, as.numeric(res$statistic)[1])
}
}
df_wilcox$p_value_corrected = p.adjust(df_wilcox$p_value_raw, method = 'holm')
df_wilcox$less_0.01 = df_wilcox$p_value_corrected < 0.01
print(paste0('Genome length: ', genome_length))
print(df_wilcox)
}## [1] "Genome length: 25"
## genome_length size_a size_b p_value_corrected p_value_raw W less_0.01
## 1 25 16 32 2.337475e-07 2.337475e-07 2883.5 TRUE
## 2 25 16 64 6.069986e-18 1.213997e-18 8607.5 TRUE
## 3 25 16 128 1.663209e-24 2.376012e-25 9258.5 TRUE
## 4 25 16 256 6.203828e-32 5.639844e-33 9896.0 TRUE
## 5 25 16 512 3.838888e-33 2.559259e-34 10000.0 TRUE
## 6 25 32 64 1.447210e-22 2.412016e-23 9074.5 TRUE
## 7 25 32 128 1.283820e-27 1.283820e-28 9542.5 TRUE
## 8 25 32 256 2.711275e-32 2.259396e-33 9927.0 TRUE
## 9 25 32 512 3.838888e-33 2.560557e-34 10000.0 TRUE
## 10 25 64 128 1.187343e-07 5.936715e-08 7219.0 TRUE
## 11 25 64 256 2.378014e-26 2.642238e-27 9430.5 TRUE
## 12 25 64 512 1.298354e-32 9.987336e-34 9954.5 TRUE
## 13 25 128 256 1.433015e-10 3.582536e-11 7710.0 TRUE
## 14 25 128 512 7.524923e-25 9.406154e-26 9294.5 TRUE
## 15 25 256 512 4.120336e-10 1.373445e-10 7627.5 TRUE
## [1] "Genome length: 50"
## genome_length size_a size_b p_value_corrected p_value_raw W less_0.01
## 1 50 16 32 2.588989e-15 5.177978e-16 1681.5 TRUE
## 2 50 16 64 2.694326e-30 2.072558e-31 228.0 TRUE
## 3 50 16 128 3.224011e-03 3.224011e-03 3794.0 TRUE
## 4 50 16 256 4.089878e-15 1.022470e-15 8284.5 TRUE
## 5 50 16 512 1.182991e-27 1.182991e-28 9545.5 TRUE
## 6 50 32 64 1.797027e-17 2.567181e-18 1427.0 TRUE
## 7 50 32 128 7.415731e-04 3.707866e-04 6457.5 TRUE
## 8 50 32 256 1.165570e-21 1.295078e-22 9005.5 TRUE
## 9 50 32 512 4.567933e-31 3.262810e-32 9836.0 TRUE
## 10 50 64 128 2.265727e-21 2.832159e-22 8973.0 TRUE
## 11 50 64 256 8.866606e-30 7.388839e-31 9727.5 TRUE
## 12 50 64 512 7.213069e-33 4.808713e-34 9979.0 TRUE
## 13 50 128 256 4.869262e-16 8.115436e-17 8409.5 TRUE
## 14 50 128 512 4.777498e-28 4.343180e-29 9582.0 TRUE
## 15 50 256 512 3.236734e-12 1.078911e-12 7914.5 TRUE
## [1] "Genome length: 100"
## genome_length size_a size_b p_value_corrected p_value_raw W less_0.01
## 1 100 16 32 7.697389e-02 1.924347e-02 4041.5 FALSE
## 2 100 16 64 3.952168e-13 7.904337e-14 1941.5 TRUE
## 3 100 16 128 2.398968e-14 2.998710e-15 1770.0 TRUE
## 4 100 16 256 4.158441e-01 4.158441e-01 5333.5 FALSE
## 5 100 16 512 5.614119e-18 4.678432e-19 8651.0 TRUE
## 6 100 32 64 1.034976e-13 1.478537e-14 1852.5 TRUE
## 7 100 32 128 3.085548e-17 3.085548e-18 1435.5 TRUE
## 8 100 32 256 1.117541e-01 3.725137e-02 5853.0 FALSE
## 9 100 32 512 2.483010e-22 1.910008e-23 9084.0 TRUE
## 10 100 64 128 1.117541e-01 4.890986e-02 4193.5 FALSE
## 11 100 64 256 5.002561e-15 5.558401e-16 8315.0 TRUE
## 12 100 64 512 5.082595e-28 3.388396e-29 9591.0 TRUE
## 13 100 128 256 1.590814e-17 1.446195e-18 8599.5 TRUE
## 14 100 128 512 9.444159e-28 6.745828e-29 9566.0 TRUE
## 15 100 256 512 2.634367e-13 4.390611e-14 8090.0 TRUE
## [1] "Genome length: 200"
## genome_length size_a size_b p_value_corrected p_value_raw W less_0.01
## 1 200 16 32 4.663546e-26 3.886289e-27 584.0 TRUE
## 2 200 16 64 7.523609e-32 5.015739e-33 100.0 TRUE
## 3 200 16 128 2.146093e-30 1.532923e-31 217.5 TRUE
## 4 200 16 256 1.997886e-24 1.911300e-25 733.0 TRUE
## 5 200 16 512 9.462181e-03 9.462181e-03 6062.5 TRUE
## 6 200 32 64 1.344008e-20 1.493343e-21 1097.0 TRUE
## 7 200 32 128 5.645064e-28 4.342357e-29 418.0 TRUE
## 8 200 32 256 1.309572e-19 1.636965e-20 1200.0 TRUE
## 9 200 32 512 2.440723e-07 6.101808e-08 7217.0 TRUE
## 10 200 64 128 1.166719e-18 1.666742e-19 1302.5 TRUE
## 11 200 64 256 9.151807e-05 3.050602e-05 3293.0 TRUE
## 12 200 64 512 6.237644e-15 1.247529e-15 8274.5 TRUE
## 13 200 128 256 9.982635e-05 4.991318e-05 6660.5 TRUE
## 14 200 128 512 1.997886e-24 1.816260e-25 9269.0 TRUE
## 15 200 256 512 1.717006e-17 2.861676e-18 8568.0 TRUE
## [1] "Genome length: 400"
## genome_length size_a size_b p_value_corrected p_value_raw W less_0.01
## 1 400 16 32 5.405382e-01 5.348472e-01 5254.5 FALSE
## 2 400 16 64 3.472338e-14 3.472338e-15 1777.5 TRUE
## 3 400 16 128 4.072814e-28 2.715209e-29 401.0 TRUE
## 4 400 16 256 1.163125e-16 9.692706e-18 1489.0 TRUE
## 5 400 16 512 5.405382e-01 1.801794e-01 5549.0 FALSE
## 6 400 32 64 5.784416e-12 8.263451e-13 2070.5 TRUE
## 7 400 32 128 1.489024e-26 1.063588e-27 535.5 TRUE
## 8 400 32 256 2.187697e-16 1.988815e-17 1523.0 TRUE
## 9 400 32 512 5.405382e-01 1.825748e-01 5546.0 FALSE
## 10 400 64 128 2.993077e-18 2.302367e-19 1317.0 TRUE
## 11 400 64 256 3.197608e-12 3.997010e-13 2030.0 TRUE
## 12 400 64 512 8.293488e-05 1.658698e-05 6763.0 TRUE
## 13 400 128 256 1.019174e-02 2.547935e-03 3764.5 FALSE
## 14 400 128 512 9.137039e-13 1.015227e-13 8045.0 TRUE
## 15 400 256 512 6.084030e-12 1.014005e-12 7918.0 TRUE